naltrue
Workflows for kickstarting RBMT in virtually No-Resource Situation
Authors: Tommi A Pirinen
Universität Hamburg,
Hamburger Zentrum für Sprachkorpora
Max-Brauer-Allee 60, Hamburg
{tommi.antero.pirinen@uni-hamburg.de}
Date:
Abstract: In this article we describe a work-in-progress best learnt practices on how to start working on rule-based machine translation when working with language that has virtually no pre-existing digital resources for NLP use. We use Karelian language as a case study, in the beginning of our project there were no publically available corpora, parallel or monolingual analysed, no analysers and no translation tools or language models. We show workflows that we have find useful to curate and develop necessary NLP resources for the language. Our workflow is aimed also for no-resources working in a sense of no funding and scarce access to native informants, we show that building core NLP resources in parallel can alleviate the problems therein.
Introduction
A lot of research goes into working with low-resource situation, however, in context of large international conferences today, loww-resources can mean anything from having millions and millions of lines of parallel corpus (footnote: http://www.statmt.org/wmt19/parallel-corpus-filtering.html) to “anything except English”. For this work we consider the lowest-resourced languages in the group of languages we work with, namely those having virtually no widely known publicly accessible or available resources at the start of our project, and for which we aim to search, curate and create the necessary resources. This is a work-in-progress, but we believe we have already gathered enough promising results to give some best recommended practices on how to start working on a language seemingly lacking all natural language processing (NLP) resources.
For the machine translation part we are working on doing a rule-based machine translation (RBMT) and specifically one between a minority language (Karelian) and a closely related more-resourced language (Finnish), in the first phase. The translator is bidirectional, i.e. we translate both Finnish to Karelian and vice versa. The work for majority language machine translations (e.g. English and Russian) is reserved for the future after some resources have been built. We have chosen this for a number of reasons, firstly the task is much easier when working with a related language than a typologically unrelated one, and secondly there is a body of good results using RBMT of closely related in further resource building, for example for Spanish-related languages in the Wikipedia content translation.
The article is organised as follows, first in Section (see: sec:background) we describe the background and rationale for this project, in Section (see: sec:workflow) we describe our approach and methodology for RBMT building, in Section (see: sec:results) we describe our results so far and finally in the Section (see: sec:conclusion) we discuss findings and lay out future work.
Background(¶ sec:background)
One of the problems, we have identified in the past in building NLP resources for minority languages, is that same or similar work ends up doing multiple times between different scholars, or even within a single project of same minority language. This is not very ideal situation, when resources like native informants or skilled scholars are scarce. A typical example might be that a documentary linguistics effort builds a corpus of annotated texts, that includes hand annotated linguistic analysis, glosses and translations, while computational linguists build a morphological analyser, treebank and machine translator by hand from scratch as well. What we aim to achieve is synergy between these two different research practices.
The technological methodology used in this project is based on following:
* The rule-based machine translation is provided by apertium [(cites: apertium)](#apertium).
* The morphological analyser-generator is based on the HFST engine [(cites: linden2009hfst)](#linden2009hfst)
* The morphological disambiguation is based on Constraint Grammar [(cites: karlsson1990constraint)](#karlsson1990constraint)
* annotation format is based on Universal dependencies [(cites: ud24)](#ud24)
This article describes what is still a work-in-progress, at this stage we are evaluating how the approach is and if we should make a project in building the supporting software for the methodology and language resource building. That is to say we have the workflows in place and the supporting software is built as we proceed with the project. Some of the workflows described here have been previously tested in building larger well-resourced machine translators, for example in (cites: pirinen2018rulebased). Based on experiences of this project, we could estimate that the effort needed is around 20,000 lines annotated and translated to get a comparable results as out of the box neural system (cites: pirinen2019neural), this is however a result achieved on two unrelated languages both of which aren’t English, so results on related non-English languages may be different.
We have selected to use a rule-based approach to machine-translation for this project. Since rule-based approaches have somewhat fallen out of popularity in recent years, it needs strong arguments to select this approach in favour of others. For this purpose we have a check-list for which languages are to be used with which approaches first:
* Closely related languages: Finnish and Karelian are very closely related languages
* Lack of Parallel resources: Karelian has virtually zero digital resources
* Existence of written grammars: We have number of grammars to help [(cites: zaikov2013vienankarjalan)](#zaikov2013vienankarjalan)
One of the reasons we started to develop an approach to language resource creation that can produce multiple language resources fast, is that we have prior experience in * building computational linguistic resources like morphological analysers from the scratch without considering the corpus creation or documentary linguistics and * building language documentation corpora from the scratch without considering creation of dictionaries.
The ideal result of this project is to develop a method that empowers computational linguists to work on their preferred form of language documentation and corpus creation and makes use of the expert work put in. This can always be achieved afterhands by scraping the produced corpora or data, but our plan is to introduce that as a part of workflow.
For other projects that have aimed to achieve similar goals, many are related to other rule-based machine translation efforts within the free/open source rule-based machine translation community, e.g.(cites: washington2014finite). On larger scale in the NLP community there have been several attempts to make computational linguists and documentary linguists work together towards common goal in this manner, for example (cites: maxwell2008joint,blokland2015language)
The basis of this RBMT system between Karelian and Finnish is that we also have a large coverage stable Finnish system already available (cites: omorfi). Karelian on the other hand has no resources, and is described by the ethnologuy as threatened (footnote: https://www.ethnologue.com/language/krl). We could have also tested an unrelated language with large coverage dictionary, for example Russian-Karelian would be useful for the target audience, or build a machine translation between two under-resourced closely related languages, like Karelian and Livvi, which is a closely related language with slightly more resources than Karelian but much less than Finnish.
Finally, for social and political reasons, there is a growing interest in Karelian language and culture, and while there is a number of projects on the linguistic aspects and language learning, there is a lack of language technology-based projects in the field. Our aim is to fill that hole.
Languages
The language we use a case study is Karelian, a minority Uralic language spoken mainly in Republic of Karelia in Russia and in Finland. It is closely related to Finnish, Livvi and Ludic, but they are not mutually intelligible for an individual without at least some linguistic training. The naming of different languages and varieties related to Karelian is often confusing, what we aim to describe here is in line of ISO 639–3 language code krl; see the number 1 in the map in Figure (see: fig:krl-map) (footnote: https://commons.wikimedia.org/wiki/File:Map_of_Karelian_dialects.png) for the geographic distribution. For the machine translation task, in first phase we build a Karelian—Finnish translator.
{kind=link}
Figure:
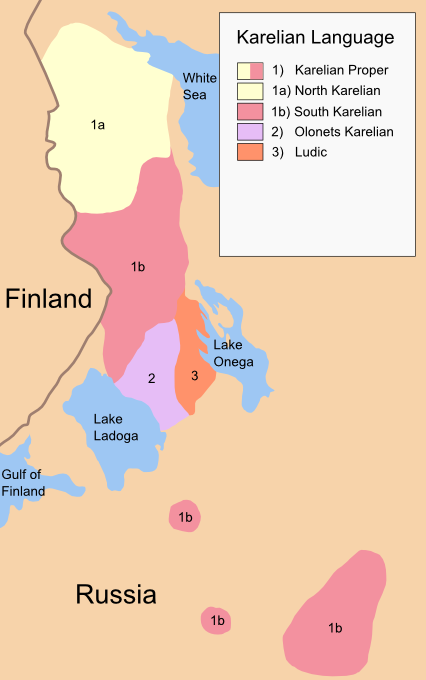 (Caption: Map of Karelian languages, the number 1 is Karelian that
we study in this article, numbers 2 and 3 are closely related languages
that are in some literature refered to as Karelian as well, but are
separate languages and do not belong under the krl language code in
ISO standard.(¶ fig:krl-map))
(Caption: Map of Karelian languages, the number 1 is Karelian that
we study in this article, numbers 2 and 3 are closely related languages
that are in some literature refered to as Karelian as well, but are
separate languages and do not belong under the krl language code in
ISO standard.(¶ fig:krl-map))
Workflow(¶ sec:workflow)
The workflow that we have reached at this point of the project is a synthesis of traditional workflow in documentary linguistics and workflows in building corpora and analyser writing, specifically in traditional rule-based systems. In documentational linguistics we have drawn experience and inspiration from SIL Fieldworks Explorer (FLeX) and the rule-based workflows are loosely based in tradition of Finite State Morphology.
The first part of the workflow is acquiring corpora, which for unresourced minority is relatively difficult task, at the beginning of our project we aimed to use web-as-corpus approach. During categorising the downloaded data into languages we found also a corpus repository with a free to use open source compatible licencing policy (footnote: http://dictorpus.krc.karelia.ru/en/corpus/text), which on top of expert made language classification has the advantage that we can keep full documents instead of shuffled sentences.
The actual corpus building workflow consists of two parts that can be alternated between, annotation and lexicon building. With annotation, we can work on any of the following tasks: lemmatising and pos tagging, morphological analysis, syntactic treebanking and machine translation. On the other side lexicon building we build the morphological lexicon for a finite-state analyser, and a bilingual lexicon for rule-based machine translation. A UML-style graph of the process is shown in figure (see: fig:translation).
Figure:
(Caption: A UML-style chart of the annotation and translation
process(¶ fig:translation))
The main contribution of this workflow is that both of the tasks feed into the other task, that is annotated corpora can be immediately used for entry generation of the lexicons, and the analysers and machine translators built from the lexicons are used to generate n-best lists from which annotators can choose the annotations.
We provide a real world example here: An annotator starts working on a new document that contains sentences: “Pelih ošallistu 13 henkie” (13 people participated in the play) the annotator annotates in UD format: \begin{scriptsize}
1 peliin peli NOUN Number=Sing|Case=Ill 2 obl _ _
2 ošallistu ošallistuo VERB Number=Sing|Tense=Pres 0 root _ _
3 13 13 NUM Number=Sing|NumType=Card 4 nummod _ _
4 henkie henki NOUN Number=Sing|Case=Par 2 nsubj _ _
\end{scriptsize}
and provides Finnish translation like “Peliin
osallistui 13 henkilöä”. The annotation is used to generate entries for
monolingual dictionary of Karelian, i.e. \verb|peli<n>|,
\verb|ošallistuo<vblex>|, \verb|13<num>|, and \verb|henki<n>|, the lexicon
writer can simply fill in the necessary informations to inflect the words
properly. The entries can likewise be generated to bilingual dictionary, if 1:1
translation match to existing target language analyses is trivial, we get
\verb|peli<n>:peli<n>| etc. among the suggested entries. Now, when the
annotator gets back to annotating and translating the next sentences of the
document and runs into: “Pelissä ”tapettih” šamoin Ilmarini” (Ilmarinen was
also killed in the game), the first token “Pelissä” has suggested annotation
peli NOUN Number=Sing|Case=Ine as well as suggested translation.
Results(¶ sec:results)
In a short time we have managed to build a rule-based machine translation system. We detail the system in Table (see: table:sizes). The corpus built so far in this proto-typing phase of the project has been built by one expert annotator, working on spare time for three months in other words in only handful of work hours.
At the current moment we do not have enough bilingual corpora to measure the translation quality yet but we hope to include a BLEU and WER evaluations of the translation quality by the time we submit a camera-ready version of the paper.
Table:
| Tokens | Sentences | |
|---|---|---|
| Annotations | 3094 | 228 |
| Translations | 1144 | 161 |
(Caption: The size of Karelian—Finnish corpus at the time of writing.(¶ table:sizes))
The corpora will be released on github via the Apertium project for the translations and possibly also disambiguated corpora, and via Universal dependencies project for the annotated corpus. Both retain the CC BY licence of the original raw text data. The dictionaries and analysers are also released via the Apertium using the GNU General Public Licence.
Concluding remarks(¶ sec:conclusion)
We have found that we can rapidly build a solid base of natural language resourcses suitable for rule-based machine translation and we aim to extend the approach to more Uralic languages in near future. Furthermore the approach prototyped in this paper has been found very motivating and nice to work with in the future we will look at building a more approachable graphical user interface for it.
The approach we describe here is especially suitable in no-resources starting situation, even a limited amount of resources will open more workflows, more technical possibilities to aid in the initial part of the corpus building and resource building. However, we still think this approach may be useful as a part of balanced corpus building approach in a research project for any lesser researched language.
One of the things that we are looking forward to is to test the advances in neural methods in very low resource situation, (cites: neubig2018rapid) (footnote: We thank the anonymous reviewers for bringing this line of work to our attention )this would be particularly suitable for Karelian-to-Finnish direction as Finnish is well-resourced.
References
- apertium:
- crossref: forcada2010apertium
- linden2009hfst:
- Author: Krister Lindén and Miikka Silfverberg and Flammie A Pirinen
- Booktitle: sfcm 2009
- Crossref: sfcm2009
- Pages: 28—47
- Title: HFST Tools for Morphology—An Efficient Open-Source Package…
- Year: 2009
- karlsson1990constraint:
- address: Helsinki
- author: Fred Karlsson
- booktitle: Proceedings of the 13th International Conference of
- editor: H. Karlgren
- pages: 168–173
- title: Constraint Grammar as a Framework for Parsing Unrestricted T…
- volume: 3
- year: 1990
- ud24:
- error: missing from bibs
- pirinen2018rulebased:
- author: Tommi A Pirinen
- booktitle: DGfS 2018: 40. Jahrestagung der Deutschen Gesellschaft für
- pages: 337
- title: Rule-based machine-translation between Finnish and German
- url: https://www.dgfs2018.uni-stuttgart.de/DGfS _2018 _booklet...
- year: 2018
- pirinen2019neural:
- author: Pirinen, Flammie A
- booktitle: Proceedings of the Fifth International Workshop on
- pages: 104–114
- title: Neural and rule-based Finnish NLP models—expectations,
- year: 2019
- zaikov2013vienankarjalan:
- author: Zaikov, Pekka
- subtitle: Lisänä harjotuk{ v{s}}ie ta lukemisto
- title: Vienankarjalan kielioppi
- year: 2013
- washington2014finite:
- address: Reykjavik, Iceland
- author: Washington, Jonathan and Salimzyanov, Ilnar and Tyers, Fra…
- booktitle: Proceedings of the Ninth International Conference on Languag…
- month: may
- pages: 3378–3385
- publisher: European Language Resources Association (ELRA)
- title: Finite-state morphological transducers for three Kypchak lan…
- url: http://www.lrec-conf.org/proceedings/lrec2014/pdf/1207_Paper…
- year: 2014
- maxwell2008joint:
- address: Hyderabad, India
- author: Michael Maxwell and Anne David
- booktitle: Workshop on NLP for Less Privileged Languages, Third
- pages: 27–34
- title: Joint Grammar Development by Linguists and Computer Scientis…
- year: 2008
- blokland2015language:
- author: Blokland, Rogier and Fedina, Marina and Gerstenberger, Cipri…
- booktitle: Septentrio Conference Series
- number: 2
- pages: 8–18
- title: Language documentation meets language technology
- year: 2015
- omorfi:
- author: Pirinen, Flammie A
- journal: SKY Journal of Linguistics
- title: Development and Use of Computational Morphology of Finnish i…
- volume: 28
- year: 2015
- neubig2018rapid:
- author: Neubig, Graham and Hu, Junjie
- journal: arXiv preprint arXiv:1808.04189
- title: Rapid adaptation of neural machine translation to new langua…
- year: 2018
Converted with Flammie’s latex2markdown v.0.1.0