Rules Ruling Neural Networks —
Neural vs. Rule-Based Grammar Checking for a Low Resource Language¹
(¹ Authors’ archival version: find original in ACL anthology)
Authors: Linda Wiechetek
UiT Norgga árktalaš
universitehta
Norway
and
{ Flammie A Pirinen UiT Norgga árktalaš
universitehta Norway
and
Mika Hämäläinen University of Helsinki,
Rootroo Ltd
Finland
and
Chiara Argese UiT Norgga árktalaš
universitehta
Norway
}
Date: (date of conversion: 2025-12-31)
Abstract:
We investigate both rule-based and machine learning methods for the task of compound error correction and evaluate their efficiency for North Sámi, a low resource language. The lack of error-free data needed for a neural approach is a challenge to the development of these tools, which is not shared by bigger languages. In order to compensate for that, we used a rule-based grammar checker to remove erroneous sentences and insert compound errors by splitting correct compounds. We describe how we set up the error detection rules, and how we train a bi-RNN based neural network. The precision of the rule-based model tested on a corpus with real errors (81.0%) is slightly better than the neural model (79.4%). The rule-based model is also more flexible with regard to fixing specific errors requested by the user community. However, the neural model has a better recall (98%). The results suggest that an approach that combines the advantages of both models would be desirable in the future. Our tools and data sets are open-source and freely available on GitHub and Zenodo.
Introduction
This paper presents our work on automatically correcting compound errors in real world text of North Sámi and exploring both rule-based and neural network methods. We chose this error type as it is the most frequent grammatical error type (after spelling and punctuation errors) and twice as frequent as the second most frequent grammatical error (agreement error). It also regards both spelling and grammar as the error is a space between two words, but its correction requires grammatical context.
A grammar checker is a writer’s tool and particularly relevant to improve writing skills of a minority language in a bilingual context, as is the case for North Sámi. According to UNESCO (cites: moseley2010atlas), North Sámi, spoken in the North of Norway, Sweden and Finland, has around 30,000 speakers. It is a low resource language in a bilingual setting, and language users frequently face bigger challenges to writing proficiency as there is always a competing language. (cites: outakoski2015davvisamegielat) Developing a reliable grammar checker with a high precision that at the same time covers a lot of errors has therefore been our main focus. Good precision (i.e. avoiding false alarms) is a priority because users get easily frustrated if a grammar checker gives false alarms and underlines correct sentences.
In this paper we focus on the correction of compound errors. This type of errors is easy to generate artificially in the absence of large amounts of error marked-up text, and we have a good amount of manually marked-up corpus for evaluation for this error type. Compound errors (i.e. one-word compounds that are erroneously written as two words) can be automatically inserted by using a rule-based morphological analyser on the corpus and splitting the word wherever we get a compound analysis. Unlike other error types (like e.g. real word errors) they are easily inserted, and existing compounds are seldom errors. In addition, they are interesting from a linguistic point of view as they are proper (complex) syntactic errors and not just spelling errors and serve as an example for higher level tools. Two adjacent words can either be syntactically related or erroneous compounds, depending on the syntax. In North Sámi orthography, as in the majority languages spoken in the region (Norwegian, Swedish and Finnish), nouns that form a new concept are usually written together. For example, the North Sámi word boazodoalloguovlu ‘reindeer herding area’ consists of three words boazu ‘reindeer’, doallu ‘industry’ and guovlu ‘area’, and thus it is written together as a single compound. The task of our methods is to correct spellings such as boazodoallu guovlu into boazodoalloguovlu in case the words have been written separately in error.
We develop both a rule-based and a neural model for the correction of compound errors. The rule-based model (GramDivvun) is based on finite-state technology and Constraint Grammar. The neural model is bi-directional recurrent (BiRNN). While the rule-based model has earlier produced good precision, it did not handle unknown compounds well, which is why we were interested in a neural approach. However, neural models depend on large amounts of ‘clean’ data and synthetic error generation (or alternatively marked-up data).
Typical for low-resource languages and also North Sámi, the corpora are not clean and contain a fair amount of a variety of different spelling and grammatical errors (see (cites: antonsen2013callinmeattahusaid)).
Therefore, efficiently preparing data as to making it available for neural model training is an important part of this paper. In our case, we make use of the existing rule-based tools to both, generate synthetic error data and clean the original data for training. For evaluation, on the other hand, we use real world error data.
Our free and open-source rule-based tools can be found on GiellaLT GitHub. (footnote: https://github.com/giellalt/) The training data and the neural models are freely available on Zenodo. (footnote: https://zenodo.org/record/5172095) We hereby want to promote a wider academic interest in conducting NLP research for the North Sámi.
Background
Sámi open source rule-based language tools have a long and successful tradition (nearly 20 years) (cites: trosterud2004porting, moshagen2011tilgjengelegheit,antonsen2011next,rueter2020fst). North Sámi is a low-resource language in terms of available corpus data (32.24M tokens raw data). Although there is a fair amount of data, it contains many real errors and only a small amount is marked up for errors.
Applying neural approaches for high-level language tasks to low resource languages is an interesting research question due the various limitations of minority language corpora, versus the existing research in the topic in well-resourced, majority languages and artificially constrained setups (cites: nekoto2020participatory). Rules have been used and are in a wide-spread use in the context of endangered Uralic languages. There is recent work on grammar checking for North Sámi (cites: wiechetek2019seeing) and spell checking for Skolt Sámi (cites: trosterud2021soft). Other rule-based approaches to grammar checking are extensively described in Wiechetek (cites: wiechetek2017when).
Before the era of neural models, it was common to use statistical machine translation (SMT) as a method for grammar error correction (cites: behera2013automated,kunchukuttan2014tuning, hoang2016exploiting). Many recent papers on grammar checking use bi-directional LSTM models that are trained to tag errors in an input sentence. Such methods have been proposed for Latvian (cites: deksne2019bidirectional), English (cites: rei-yannakoudakis-2016-compositional) and Chinese (cites: huang2016bi). Similar LSTM based approaches have also been applied for error correction (cites: yuan2016grammatical,ge2019automatic,jahan2021bangla). Other recent approaches (cites: kantor2019learning,omelianchuk2020gector) use methods that take advantage of BERT (cites: devlin-etal-2019-bert) and other data-hungry models. While such rich sentence embeddings can be used for English and a few other languages with a large amount of data, their use is not viable for North Sámi.
Data
For evaluation and training the neural model we use the (cites: sikor_06.11.2018) (the Sámi International KORpus), which is a collection of texts in different Sámi languages compiled by UiT The Arctic University of Norway and the Norwegian Sámi Parliament. It consists of two subcorpora: GT-Bound (footnote: https://gtsvn.uit.no/boundcorpus/orig/sme/) (texts limited by a copyright which are available only by request) and GT-Free (footnote: https://gtsvn.uit.no/freecorpus/orig/sme/) (the publicly available texts). As a preprocessing step, we run a rule-based grammar checker (cites: wiechetek2012constraint) and remove sentences with potential compound errors, as we cannot automatically ensure whether these errors are real or not. This is needed as we want this data to be fully free of any compound errors as it serves as the target side of our neural model.
Thereafter, we take in each sentence in this error free data and analyse it by a
rule-based morphological
analyser (footnote: https://github.com/giellalt/lang-sme). When the analyser
sees a potential compound word, it indicates the word boundary with a compound
(+Cmp\#) tag. We use this information to automatically split all
compounds identified by the rule-based analyser. This results in a parallel
corpus of the original sentences as the prediction target and their
corresponding versions with synthetically introduced compound errors. Many of
the compound boundaries are ambiguous, and the algorithm decides the one used in
training data based on heuristics: maximum number of compound boundaries where
the splitting will not cause any other modifications of the word stems or other
content.
As an additional data source, we use the North Sámi Universal Dependencies treebank (cites: tyers-sheyanova-2017-annotation). We parse the corpus with UralicNLP (cites: uralicnlp) and split the compounds the rule-based morphological analyser identifies as consisting of two or more words in order to synthetically introduce errors. We also run the rule-based morphological analyser and morpho-syntactic disambiguator to add part-of-speech (POS) information to produce an additional data set with POS tags. For the Universal Dependencies data, we use the POS tags provided in the data set.
We then make sure that all sentences have at least one generated compound error and that the only type of error the sentences have is the compound error (no other changes introduced by the rule-based models). We shuffle this data randomly and split it on a sentence level into 70 % training, 15 % validation and 15 % testing. The size of the data set can be seen in Table (see: tab:data-stats), the sentences were tokenized based on punctuation marks.
Table:[htb]
| Sentences | Source tokens | —- | —- | —- | ||
| Train | 43,658 | 388,167 | ||||
| Test | 9,356 | 83,107 | ||||
| Validation | 9,355 | 82,566 | ||||
| Real-world errors | 3,291 | 26,565 |
(Caption: Training, testing and validation sizes for the neural model (corpus with synthetic errors)(¶ tab:data-stats))
For the rule-based model GramDivvun we do not generate synthetic errors. We have hand-selected a large corpus for rule development and as regression tests, consisting of representative sentences from GT-Free. The current selection for syntactic compound errors includes 3,291 sentences with real world compound errors (and possibly other errors in addition).
Methods
We use a neural models and a rule-based model for compound error correction.
Neural Model
Table:[htb]
|}
| —- | —- | —- | —- |
| n | Input | Output |
| 2 | g e a h č č a l a d d a n _ p r o š e a k t a n | g e a h č č a l a d d a n p r o š e a k t a n |
| 3 | g e a h č č a l a d d a n _ p r o š e a k t a n _ p r o š e a k t a n | g e a h č č a l a d d a n p r o š e a k t a n _ p r o š e a k t a n |
| 2 | V> g e a h č č a l a d d a n <V _ N> p r o š e a k t a n <N | g e a h č č a l a d d a n p r o š e a k t a n |
| 3 | [c]{@l@}V> g e a h č č a l a d d a n <V _ N> p r o š e a k t a n <N _ | N> j a g i <N
& g e a h č č a l a d d a n p r o š e a k t a n _ p r o š e a k t a n
\hline
\end{tabular}
(Caption: Examples of the character-level input and output, where n
indicates the chunk size. The first examples are without POS tags and the
last with POS tags(¶ tab:example-input-output))
We model the problem at a character instead of word level in NMT (neural machine translation). The reason for using a character-level model instead of a word-level model is that, this way, the model can work better with out-of-vocabulary words. This is important due to the low-resourced nature of North Sámi, although there are other deep learning methods for endangered languages that do not utilize character level models (cites: alnajjar2021when). In practice, we split words into characters separated by white spaces and mark actual spaces between words with an underscore (_). We train the model to predict from text with compound errors into text without compound errors. As previous research (cites: partanen-etal-2019-dialect,alnajjar2020automated) has found that using chunks of words instead of full sentences at a time improves the results in character level models, we will be training different models with different chunk sizes. This means that we will train a model to predict two words at a time, three words at a time, all the way to five words at a time.
We train the models with and without POS tags. For the models with POS tags, we surround each word with a token indicating the beginning and the end of the POS tag. The POS tags are included only on the source side, not on the target side. They are separated from the word with a white space.
An example of the data can be seen in Table (see: tab:example-input-output). Even though every sentence in the training data has a compound error, this does not mean that every input chunk the model sees would have a compound error. This way, the model will also learn to leave the input unchanged if no compound errors are detected.
We train all models using a bi-directional long short-term memory (LSTM) based model (cites: hochreiter1997long) by using OpenNMT-py (cites: opennmt) with the default settings except for the encoder where we use a BiRNN (cites: schuster1997bidirectional) instead of the default RNN (recurrent neural network), since BiRNN based models have been shown to provide better results in character-level models (cites: hamalainen2019revisiting). We use the default of two layers for both the encoder and the decoder and the default attention model, which is the general global attention presented by (cites: luong2015effective). The models are trained for the default of 100,000 steps. All models are trained with the same random seed (3,435) to ensure reproducibility.
During the training of the neural models, we evaluate the models using simple sentence level scores. There we look only at full-sentence matches and evaluate their accuracy, precision and recall, as opposed to the evaluations in Section (see: sec:evaluation), where we study them more carefully at the word-level. The results of the neural models for the generated corpus (where errors were introduced by splitting compounds) can be seen in Table (see: tab:results-neural). The results indicate that both of the models receiving a chunk of two words at a time reached to the highest accuracy, and the model without the POS tags also reached to the highest precision.
Table:[htb]
| Chunk | POS | Accuracy | Precision | \bf | ||
| Recall | —- | —- | —- | —- | —- | |
| 2 | no | 0.925 | 0.949 | 0.974 | ||
| 3 | no | 0.847 | 0.883 | 0.955 | ||
| 4 | no | 0.852 | 0.892 | 0.950 | ||
| 5 | no | 0.869 | 0.909 | 0.952 | ||
| 2 | yes | 0.925 | 0.948 | 0.976 | ||
| 3 | yes | 0.906 | 0.934 | 0.968 | ||
| 4 | yes | 0.856 | 0.896 | 0.951 | ||
| 5 | yes | 0.857 | 0.895 | 0.953 |
(Caption: Sentence level scores for different neural models tested on a corpus with artificially introduced errors(¶ tab:results-neural))
The POS tags were not important for the models, as the results with and without them are fairly similar. The largest gain was when the compound error correction was done for three words at a time. As this performance gain only occurred for that specific model, it suggests that it is more of an artefact of the training data and how it is fed into the model than any actual improvement.
Rule-based Model
The rule-based grammar checker GramDivvun is a full-fledged grammar checker fixing spelling errors, (morpho)-syntactic errors (including real word spelling errors (footnote: Real word errors are spelling errors where the outcome is an actual word that is not fit for the context.), inflection errors, and compounding errors) and punctuation and spacing errors.
It takes input from the finite-state transducer (FST) to a number of other modules, the core of which are several Constraint Grammar modules for tokenization disambiguation, morpho-syntactic disambiguation and a module for error detection and correction. The full modular structure (Figure (see: fig:my_label)) is described in Wiechetek (cites: wiechetek2019seeing). This work regards predominantly the modification of the disambiguation and error detection modules mwe-dis.cg3, grc-disambiguator.cg3, and grammerchecker-release.cg3. We are using finite-state morphology (cites: beesley2003finite) to model word formation processes. The technology behind our FSTs is described in Pirinen (cites: pirinen2010finitestate). Constraint Grammar is a rule-based formalism for writing disambiguation and syntactic annotation grammars (cites: karlsson1990constraint,karlsson1995constraint). In our work, we use the free open source implementation VISLCG-3 (cites: didriksen2015cg3). All components are compiled and built using the GiellaLT infrastructure (cites: moshagen-etal-2013-building). The code and data for the model is available for download (footnote: https://github.com/giellalt/lang-sme/releases/tag/naacl-2021-ws) with specific version tagged for reproducibility.
Figure:[ht]
<div style='text-align: center'>
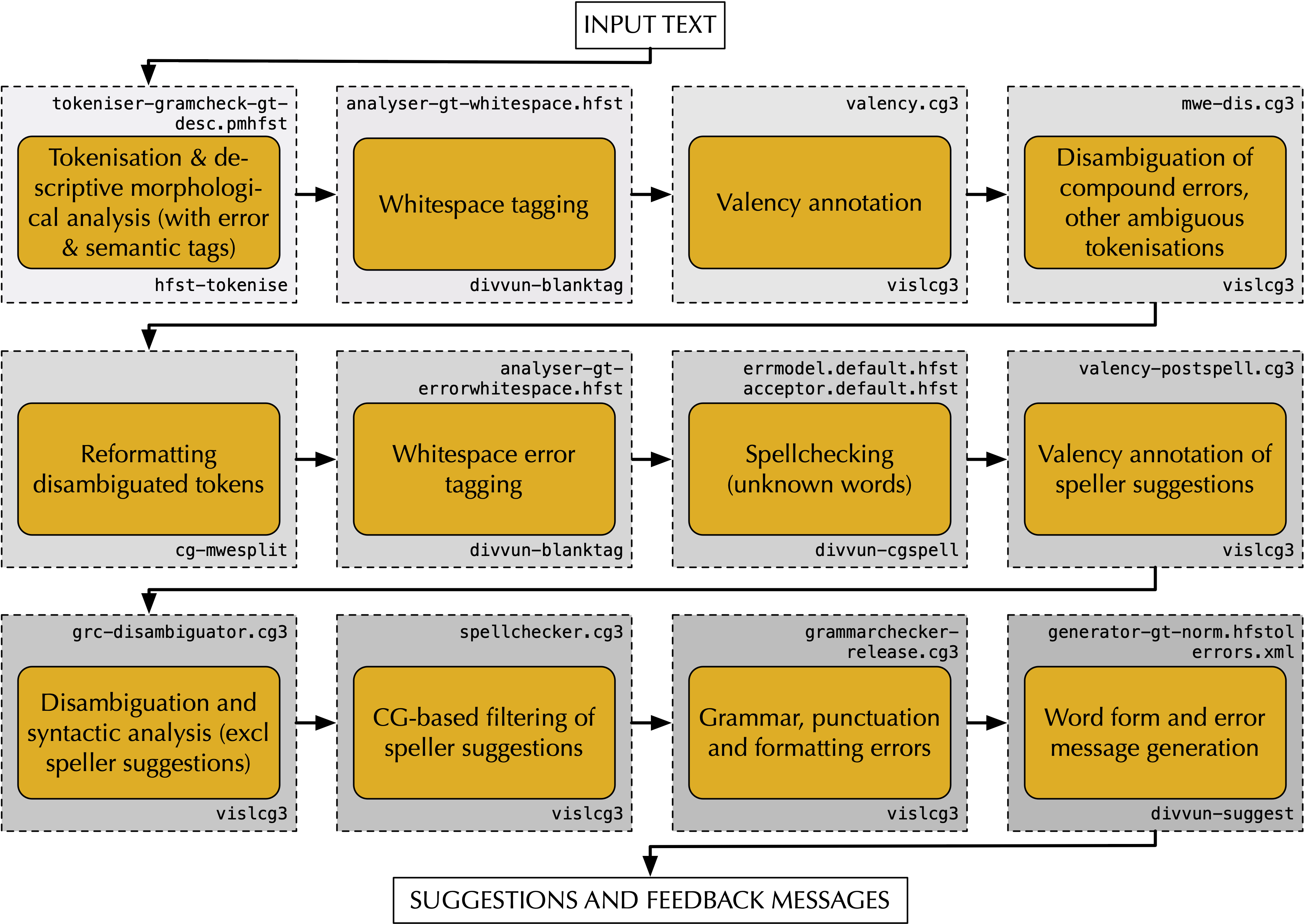 (Caption: System architecture of the North Sámi grammar checker
(GramDivvun)(¶ fig:my_label))
</div>
(Caption: System architecture of the North Sámi grammar checker
(GramDivvun)(¶ fig:my_label))
</div>
The syntactic context is specified in hand-written Constraint Grammar rules. The
REMOVE-rule below removes the compound error reading (identified by the tag
Err/SpaceCmp) if the head is a 3rd person singular verb (cf. l.2) and
the first element of the potential compound is a noun in nominative case (cf.
l.3). The context condition further specifies that there should be a finite verb
(VFIN) somewhere in the sentence (cf. l.4) for the rule to apply.
[frame=single,framerule=0.2mm,framesep=3mm,fontsize=<!-- footnotesize -->,baselinestretch=1]
REMOVE (Err/SpaceCmp)
(0/0 (V Sg3))
(0/1 (N Sg Nom))
(*0 VFIN);
All possible compounds written apart are considered to be errors by default, unless the lexicon specifies a two or several word compound or a syntactic rule removes the error reading.
The process of rule writing includes several consecutive steps, and like neural network models they require data. The process is as follows:
* Modelling an error detection rule based on at least one actual sentence containing the error
* Adding constraints based on the linguist’s knowledge of possible contexts (remembered data)
* A corpus search for sentences containing similar forms/errors, testing of the rule and reporting rule mistakes
* Modification of constraints in the rule based on this data and testing against regression tests so that unfit constraints depending on results for precision and recall (focus on precision)
The basis of rule development is continuous integration. Typical shortcomings and bad errors can be fixed right away with added conditions. Neural models are not usually trained in this way.
The frequent experience of false alarms can decrease the users’ trust in the grammar checker. Typically, full-fledged user oriented grammar checkers, e.g. DanProof focus on keeping false alarms low and precision high (cites: bick2015danproof) because users’ experiences have shown that certain experiences will frustrate users and stop them from using the application.
For rule development, regression tests are used. These consist in error-specific YAML (footnote: https://yaml.org/spec/1.2/spec.html) tests and are manually marked up.
The regression test for compound errors contains 3,291 sentences (1,368 compound errors, used for development and regression) give the results as shown in Table (see: tab:rule_based_res).
Table:[htb]
| Precision | Recall | F_1 score |
|---|---|---|
| 94.95 | 86.22 | 90.80 |
(Caption: The rule-based model tested on the developer’s corpus (regression tests)(¶ tab:rule_based_res))
Results(¶ sec:evaluation)
We evaluate the models both quantitatively and qualitatively. We evaluate on accuracy, precision and recall, and do a linguistic evaluation. The measurements are defined in this article as follows: Accuracy A = \frac{C}{S}, where C is a correct sentence (1:1 string match) and S is corpus size in sentences, precision P = \frac{tp}{tp + fp} and recall R = \frac{tp}{tp + fn}, where tp is true positive, fp is false positive and fn is false negative. The F_1 score is the harmonic mean of precision and recall F_1 = 2 \times \frac{P \times R}{P + R}. The accuracy is thus sentence level correctness rate—as used in the method section to probe model qualities—whereas precision measures how often corrections were right and recall measures how many errors we found. The word-level errors are counted once per error in the marked-up corpus. Thus, if a three-part compound contains two compounding errors it is counted towards the total as one error, but if a sentence has three separate compounds with wrong splits each, we count three errors.
The error marked-up corpus we used includes 140 syntactic compound errors (there are other compound errors that can be discovered by the spellchecker as they are word internal) and is from GT-Bound. We chose GT-Bound to make sure that the sentences had not been used to develop rules. It is part of our error-marked up corpus, which makes it possible to run an automatic analysis. This error corpus does only contain real world (as opposed to synthetic) errors.
Table:[htb]
| Chunk | POS | Accuracy | Precision | |||
| Recall | —- | —- | —- | —- | —- | |
| 2 | no | 0.781 | 0.794 | 0.980 | ||
| 3 | no | 0.707 | 0.720 | 0.974 | ||
| 4 | no | 0.726 | 0.747 | 0.963 | ||
| 5 | no | 0.727 | 0.757 | 0.950 | ||
| 2 | yes | 0.777 | 0.788 | 0.982 | ||
| 3 | yes | 0.761 | 0.775 | 0.976 | ||
| 4 | yes | 0.720 | 0.744 | 0.958 | ||
| 5 | yes | 0.751 | 0.765 | 0.976 |
(Caption: Sentence level scores for the neural models tested on a real world error corpus(¶ tab:neural-real-world-res))
Table (see: tab:neural-real-world-res) shows the results for the neural models on this corpus. The drop in results is expected as the models were trained on synthetic data, whereas this data consists of real world errors. However, the results stay relatively good, given that synthetic data was the only way to produce enough training data for North Sámi.
We ran the neural and rule-based model on two different corpora of compound error materials, i.e. synthetic and real world. Table (see: tab:my_label) shows the evaluation on a real world error corpus.
Table:[htb]
| Model | Precision | Recall | F_1 |
|---|---|---|---|
| Rule-based model | 81.0 | 60.7 | 69.3 |
| Neural model | 79.4 | 98.0 | 87.7 |
(Caption: Results for both models based on a manually marked-up evaluation corpus(¶ tab:my_label))
The neural network performs well in terms of numbers, but has the following shortcomings that are problematic for the end users. It introduces new (types of) errors unrelated to compounding, like changing km² randomly either to kmy or km kind of unforgivable (because not understandable) for the end user. They introduce compounds like Statoileamiálbmogiid ‘Statoil (national oil company and gasstation) indigenous people’ as in ex. (see: statoil). The rule-based grammar checker presupposes that the compound is listed in the lexicon, which is why these corrections can easily be avoided.
Linguistic example group:
Statoil eamiálbmogiid eatnamiid billisteami birra(¶ statoil)
Statoil indigenous.people.acc.pl land.acc.pl destruction.gen about
‘about the destruction of the indigenous peoples’ territories by Statoil’
It also produces untypically long non-sense words like NorggaSámiidRiidRiidRiidRiidRiidRiidRiikasearvvi. In addition, there are false positives of certain grammatical combinations that are systematically avoided by rule-based grammar checker. These are combinations of attributive adjectives and nouns (17 occurrences) like boares eallinoainnuid in ex. (see: boareseallinoainnuid) and genitive modifier and noun combinations (11 occurrences) like njealjehaskilomehtera eatnamat in ex. (see: njealjehas).
Linguistic example group:
boares eallinoainnuid ja modearna servodaga váikkuhusaid gaskii.(¶ boareseallinoainnuid)
old life.view.acc.pl and modern society.gen impact.acc.pl between
‘between old philosophies and the impact of modern society’
Linguistic example group:
Dasalassin 137000 njealjehaskilomehtera eatnamat biđgejuvvojit seismalaš linnjáid(¶ njealjehas)
in.addition 137000 square.kilometre.gen landpl. split.pass.pl3 seismic line.acc.pl
‘In addition, 137,000 square kilometres of land are split by seismic lines’
The rule-based model, on the other hand, typically suggests compounding, where both compounding and two word combinations would be adequate, for example in the case of the first part of the compound having homonymous genitive and a nominative analyses. The suggested compound is not an error. However, the written form is grammatically correct as well. These suggestions still count as false positives. Other typical errors are cases where there are two accepted ways of spelling a compound/MWE as in ex. (see: ridduriddu), where both Riddu Riđđu and Riddu-Riđđu are correct spellings, and the latter one is suggested as a correction of the former one.
Linguistic example group:
ovdanbuktojuvvojit omd. jahkásaš Riddu Riđđu festiválas.(¶ ridduriddu)
present.pass.prs.pl3 e.g. annual {Riddu Riđđu} festival.loc
‘they are presented at the annual Riddu Riđđu festival.
The rule-based model also struggles predominantly with false negatives, like njunuš olbmot ‘leading people’ that are due to missing entries in the lexicon like in ex. (see: njunus).
Linguistic example group:
Sii leat gieldda njunuš olbmot.(¶ njunus)
they are municipality.gen leading people
‘They are the leading people of the municipality’
Discussion
In the future, we would like to look into hybrid grammar checking of other error types and other (Sámi) languages.
The neural approach gives us relatively high recall in the real world situation with lower precision, whereas the rule-based model is designed to give us high precision even at the cost of lower recall (user experience), which is why hybrid approaches that combine the best of two worlds are interesting.
Noisy data is to be expected in any endangered language context, as the language norms are to a lesser degree internalized. We will therefore need a way of preparing the data to train neural networks, which can either consist in creating synthetic data or automatically fixing errors and creating a parallel corpus.
When creating synthetic data for neural networks, the amount of data is hardly the main issue. Many generative systems are capable of over-generating data. The main question that arises is the quality and representatives ((cites: hamalainen2019template)) of the generated data. If the rules used to generate the data are not in line with the real world phenomenon the neural model is meant to solve, we cannot expect very high quality results in real world data.
Generated sentences can easily be less complex ‘text book examples’ that are not representative of real world examples. In the case of agreement errors between subjects and verbs, for example, there are long distance relationships and complex coordinated subjects including personal pronouns that can change the structure of a seemingly straightforward relation. Therefore, we advocate the use of high quality rule-based tools to prepare the data, i.e. fix the errors and create a parallel corpus.
While synthetic error data generation for compound errors is somewhat more straightforward as it only affects adjacent words, the generation of synthetic error corpora for other error types is not as straightforward, in part also because generating synthetic errors of other kind can potentially create valid and grammatically correct sentences with different meanings. We therefore predict that (hybrid) neural network approaches for other error types that either involve specific morphological forms (of which there are many in North Sámi) or changes in word order will be more difficult to resolve.
Conclusion
In this paper, we have developed both a neural network and a rule-based grammar checker module for compound errors in North Sámi. We have shown that a neural compound-corrector for a low-resource language can be built based on synthetic error data by introducing the compound errors using a high level rule-based grammar models. It is based on the rule-based tools to both generate errors and clean the data using both part-of-speech analysis, disambiguation and even the error detector.
The rule-based module is embedded in the full-fledged GramDivvun grammar checker and achieves a good precision of 81% and a lower recall of 61%. A higher precision, even at the cost of a lower recall, is in line with our objective of keeping false alarms low, so users will be comfortable using our language tools. The neural network achieves a slightly lower precision of 79% and a much higher recall of 98%.
However, the rule-based model has more user-friendly suggestions and some false positives are simply other correct alternatives to the ones in the text, while the neural network’s false positives sometimes introduce new and unrelated errors. On-the-fly fixes that avoid false positives are an advantage of rule-based models. Rule-based models, on the other hand, are not so good at recognizing unknown combinations. Hybrid models that combine the benefits of both approaches are therefore desirable for efficient compound error correction in the future.
Acknowledgments
Thanks to Børre Gaup for his work on the evaluation script. Some computations were performed on resources provided by UNINETT Sigma2 — the National Infrastructure for High Performance Computing and Data Storage in Norway.
References
- moseley2010atlas:
- edition: 3rd
- editor: Moseley, Christopher
- note: Online version: http://www.unesco.org/languages-atlas/
- place: Paris
- publisher: UNESCO Publishing
- title: Atlas of the World’s Languages in Danger
- year: 2010
- outakoski2015davvisamegielat:
- author: Outakoski, Hanna
- editor: Jussi Ylikoski, Lene Antonsen, Vuokko Hirvonen, Johan Klemet
- journal: Sámi dieđalaš áigečála
- pages: 29–59
- title: Davvisámegielat čálamáhtu konteaksta [{The} context of {Nort…
- volume: 1/2015
- year: 2013
- antonsen2013callinmeattahusaid:
- author: Antonsen, Lene
- journal: University of Tromsø
- note: [English summary: Tracking misspellings.]
- title: Cállinmeattáhusaid guorran.
- year: 2013
- trosterud2004porting:
- author: Trosterud, Trond
- booktitle: SALTMIL Workshop at LREC 2004: First Steps in Language
- organization: Citeseer
- pages: 90–92
- title: Porting morphological analysis and disambiguation to new lan…
- year: 2004
- **
moshagen2011tilgjengelegheit**:
- error: missing from bibs
- antonsen2011next:
- author: Antonsen, Lene and Trosterud, Trond
- booktitle: Proceedings of the NODALIDA 2011 Workshop Constraint Grammar
- pages: 1–7
- title: Next to nothing–a cheap South Saami disambiguator
- year: 2011
- rueter2020fst:
- author: Rueter, Jack and Hämäläinen, Mika
- booktitle: Proceedings of the 1st Joint Workshop on Spoken LanguageTech…
- pages: 250–257
- title: FST Morphology for the Endangered Skolt Sami Language
- year: 2020
- nekoto2020participatory:
- address: Online
- author: Nekoto, Wilhelmina and Marivate, Vukosi and Matsila,Tshino…
- booktitle: Findings of the Association for Computational Linguistics:
- doi: 10.18653/v1/2020.findings-emnlp.195
- month: nov
- pages: 2144–2160
- publisher: Association for Computational Linguistics
- title: Participatory Research for Low-resourced Machine Translation…
- url: https://www.aclweb.org/anthology/2020.findings-emnlp.195
- year: 2020
- wiechetek2019seeing:
- author: Wiechetek, Linda and Moshagen, Sjur and Unhammer, Kevin Brub…
- booktitle: Proceedings of the 3rd Workshop on the Use of Computational
- pages: 46–55
- title: Seeing more than whitespace—Tokenisation and disambiguation …
- year: 2019
- trosterud2021soft:
- author: Trosterud, Trond and Moshagen, Sjur
- booktitle: Multilingual Facilitation
- editor: Mika Hämäläinen and Niko Partanen and Khalid Alnajjar
- language: English
- pages: 197-207
- publisher: Rootroo Ltd
- title: Soft on errors? The correcting mechanism of a Skolt Sami
- year: 2021
- wiechetek2017when:
- author: Linda Wiechetek
- school: UiT The Arctic University of Norway
- title: When grammar can’t be trusted – Valency and semantic catego…
- type: {PhD} Thesis
- year: 2017
- behera2013automated:
- author: Behera, Bibek and Bhattacharyya, Pushpak
- booktitle: Proceedings of the Sixth International Joint Conference on
- pages: 937–941
- title: Automated grammar correction using hierarchical phrase-based
- year: 2013
- kunchukuttan2014tuning:
- author: Kunchukuttan, Anoop and Chaudhury, Sriram and Bhattacharyya,
- booktitle: Proceedings of the Eighteenth Conference on Computational
- pages: 60–64
- title: Tuning a grammar correction system for increased precision
- year: 2014
- **
hoang2016exploiting**:
- error: missing from bibs
- deksne2019bidirectional:
- author: Deksne, Daiga
- booktitle: International Conference on Text, Speech, and Dialogue
- organization: Springer
- pages: 58–68
- title: Bidirectional LSTM tagger for Latvian grammatical error dete…
- year: 2019
- rei-yannakoudakis-2016-compositional:
- address: Berlin, Germany
- author: Rei, Marek and Yannakoudakis, Helen
- booktitle: Proceedings of the 54th Annual Meeting of the Association fo…
- doi: 10.18653/v1/P16-1112
- month: aug
- pages: 1181–1191
- publisher: Association for Computational Linguistics
- title: Compositional Sequence Labeling Models for Error Detection i…
- url: https://www.aclweb.org/anthology/P16-1112
- year: 2016
- huang2016bi:
- author: Huang, Shen and Wang, Houfeng
- booktitle: Proceedings of the 3rd Workshop on Natural Language Processi…
- pages: 148–154
- title: Bi-LSTM neural networks for Chinese grammatical error diagno…
- year: 2016
- yuan2016grammatical:
- author: Yuan, Zheng and Briscoe, Ted
- booktitle: Proceedings of the 2016 Conference of the North AmericanChap…
- pages: 380–386
- title: Grammatical error correction using neural machine translatio…
- year: 2016
- ge2019automatic:
- author: Ge, Tao and Zhang, Xingxing and Wei, Furu and Zhou, Ming
- booktitle: Proceedings of the 57th Annual Meeting of the Association fo…
- pages: 6059–6064
- title: Automatic grammatical error correction for sequence-to-seque…
- year: 2019
- jahan2021bangla:
- author: Jahan, Mir Noshin and Sarker, Anik and Tanchangya, Shubra an…
- booktitle: Proceedings of International Conference on Trends in
- organization: Springer
- pages: 3–13
- title: Bangla Real-Word Error Detection and Correction Using
- year: 2021
- kantor2019learning:
- author: Kantor, Yoav and Katz, Yoav and Choshen, Leshem and Cohen-Ka…
- booktitle: Proceedings of the Fourteenth Workshop on Innovative Use of
- pages: 139–148
- title: Learning to combine Grammatical Error Corrections
- year: 2019
- omelianchuk2020gector:
- author: Omelianchuk, Kostiantyn and Atrasevych, Vitaliy and Chernodu…
- booktitle: Proceedings of the Fifteenth Workshop on Innovative Use of N…
- pages: 163–170
- title: GECToR–Grammatical Error Correction: Tag, Not Rewrite
- year: 2020
- devlin-etal-2019-bert:
- address: Minneapolis, Minnesota
- author: Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and
- booktitle: Proceedings of the 2019 Conference of the North American
- doi: 10.18653/v1/N19-1423
- month: jun
- pages: 4171–4186
- publisher: Association for Computational Linguistics
- title: BERT: Pre-training of Deep Bidirectional Transformers for
- url: https://www.aclweb.org/anthology/N19-1423
- year: 2019
- sikor_06.11.2018:
- author: SIKOR
- title: SIKOR UiT Norgga árktalaš universitehta ja Norgga Sámedikki …
- howpublished: url{http://gtweb.uit.no/korp}
- note: Accessed: 2024-10-01
- year: 2021
- wiechetek2012constraint:
- address: Istanbul, Turkey
- author: Linda Wiechetek
- booktitle: Proceedings of the Workshop on Language Technology for
- date: 22
- editor: G. De Pauw and G-M de Schryver and M.L. Forcada and K. Saras…
- month: may
- pages: 35–40
- publisher: European Language Resources Association (ELRA)
- title: {Constraint Grammar} based correction of grammatical errors …
- year: 2012
- tyers-sheyanova-2017-annotation:
- address: St. Petersburg, Russia
- author: Tyers, Francis M. and Sheyanova, Mariya
- booktitle: Proceedings of the Third Workshop on Computational Linguisti…
- doi: 10.18653/v1/W17-0607
- month: jan
- pages: 66–75
- publisher: Association for Computational Linguistics
- title: Annotation schemes in North Sámi dependency parsing
- url: https://www.aclweb.org/anthology/W17-0607
- year: 2017
- uralicnlp:
- DOI: 10.21105/joss.01345
- author: Mika Hämäläinen
- journal: Journal of Open Source Software
- number: 37
- pages: 1345
- title: {UralicNLP}: An NLP Library for Uralic Languages
- volume: 4
- year: 2019
- alnajjar2021when:
- address: Finland
- author: Khalid Alnajjar
- booktitle: Multilingual Facilitation
- doi: 10.31885/9789515150257
- editor: Mika Hämäläinen and Niko Partanen and Khalid Alnajjar
- language: English
- month: mar
- pages: 275–288
- publisher: Rootroo Ltd
- title: When Word Embeddings Become Endangered
- year: 2021
- partanen-etal-2019-dialect:
- error: missing from bibs
- alnajjar2020automated:
- author: Alnajjar, Khalid and Hämäläinen, Mika and Partanen,
- journal: arXiv preprint arXiv:2010.05269
- title: Automated Prediction of Medieval Arabic Diacritics
- year: 2020
- hochreiter1997long:
- author: Hochreiter, Sepp and Schmidhuber, Jürgen
- journal: Neural computation
- number: 8
- pages: 1735–1780
- publisher: MIT Press
- title: Long short-term memory
- volume: 9
- year: 1997
- opennmt:
- author: Guillaume Klein and Yoon Kim and Yuntian Deng and Jean Senel…
- booktitle: Proc. ACL
- doi: 10.18653/v1/P17-4012
- title: OpenNMT: Open-Source Toolkit for Neural Machine Translation
- url: https://doi.org/10.18653/v1/P17-4012
- year: 2017
- schuster1997bidirectional:
- author: Schuster, Mike and Paliwal, Kuldip K
- journal: IEEE transactions on Signal Processing
- number: 11
- pages: 2673–2681
- publisher: Ieee
- title: Bidirectional recurrent neural networks
- volume: 45
- year: 1997
- hamalainen2019revisiting:
- author: Hämäläinen, Mika and Säily, Tanja and Rueter,
- booktitle: Proceedings of the 3rd Joint SIGHUM Workshop on Computationa…
- pages: 71–75
- title: Revisiting NMT for Normalization of Early English Letters
- year: 2019
- luong2015effective:
- author: Luong, Minh-Thang and Pham, Hieu and Manning, Christopher D
- journal: arXiv preprint arXiv:1508.04025
- title: Effective approaches to attention-based neural machine trans…
- year: 2015
- beesley2003finite:
- author: Kenneth R Beesley and Lauri Karttunen
- flammie: fsa
- isbn: 978-1575864341
- pages: 503
- publisher: CSLI publications
- title: Finite State Morphology
- year: 2003
- pirinen2010finitestate:
- address: Valletta, Malta
- author: Tommi A Pirinen and Krister Lindén
- booktitle: Proceedings of the Seventh SaLTMiL workshop on creation and
- category: thesis
- flammie: spell-checking
- pages: 13–18
- title: Finite-State Spell-Checking with Weighted Language and Error
- url: http://siuc01.si.ehu.es/%7Ejipsagak/SALTMIL2010 _Proceeding…
- year: 2010
- karlsson1990constraint:
- address: Helsinki
- author: Fred Karlsson
- booktitle: Proceedings of the 13th International Conference of
- editor: H. Karlgren
- pages: 168–173
- title: Constraint Grammar as a Framework for Parsing Unrestricted T…
- volume: 3
- year: 1990
- karlsson1995constraint:
- address: Berlin
- author: Fred Karlsson and Atro Voutilainen and Juha Heikkilä and Art…
- publisher: Mouton de Gruyter
- title: Constraint Grammar: A Language-Independent System for Parsin…
- year: 1995
- didriksen2015cg3:
- author: Bick, Eckhard and Didriksen, Tino
- booktitle: Proceedings of the 20th Nordic Conference of Computational
- editor: Beáta Megyesi
- issn: 1650-3740
- pages: 31–39
- publisher: Linköping University Electronic Press, Linköpings universite…
- title: {CG-3} – Beyond Classical {Constraint Grammar}
- year: 2015
- moshagen-etal-2013-building:
- address: Oslo, Norway
- author: Moshagen, Sjur N. and Pirinen, Flammie and Trosterud, Tron…
- booktitle: Proceedings of the 19th Nordic Conference of Computational
- month: may
- pages: 343–352
- publisher: Linköping University Electronic Press, Sweden
- title: Building an Open-Source Development Infrastructure for Langu…
- url: https://www.aclweb.org/anthology/W13-5631
- year: 2013
- bick2015danproof:
- address: Hissar, Bulgaria
- author: Eckhard Bick
- booktitle: Proceedings of the 10th International Conference Recent
- editor: Galia Angelova and Kalina Bontcheva and Ruslan Mitkov
- pages: 55–62
- publisher: INCOMA Ltd.
- title: {DanProof}: Pedagogical Spell and Grammar Checking for {Dani…
- year: 2015
- hamalainen2019template:
- address: New York, NY, USA
- author: H “{a}m “{a}l “{a}inen, Mika and Alnajjar, Khalid
- booktitle: Proceedings of the 2019 2nd International Conference on
- doi: 10.1145/3377713.3377801
- isbn: 9781450372619
- keywords: Synthetic templates, Machine translation, Endangered languag…
- location: Sanya, China
- numpages: 6
- pages: 520–525
- publisher: Association for Computing Machinery
- series: ACAI 2019
- title: A Template Based Approach for Training NMT for Low-Resource …
- url: https://doi.org/10.1145/3377713.3377801
- year: 2019
Converted with Flammie’s latex2markdown v.0.1.0